主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
好处:
缺点:
- 复制延迟
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
指定主机命令:slaveof 主机ip 主机端口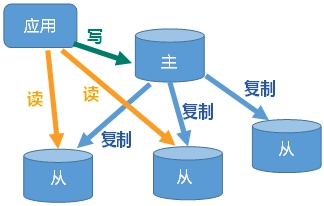
一主二仆
- 从服务器挂掉后重启时,变为主服务器
- 从服务器挂掉后重启时,再加入从服务器中,会把主服务器中的数据从头到尾复制一遍
- 主服务器挂掉后,从服务器不会变成主服务器
- 主服务器挂掉后重启,还是主服务器
薪火相传
- 上一个Slave可以是下一个Slave的Master,Slave同样可以接收其他 slaves的连接和同步请求, 可以有效减轻master的写压力,去中心化降低风险。
反客为主
slaveof no one当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
复制原理
1、从服务器连接上主服务器之后,就会发送进行数据同步的消息。
2、主服务器收到从服务器发送过来的消息后,把主服务器中的数据进行持久化为RDB文件,把RDB文件发送给从服务器。
3、每次主服务器写操作时,主动和从服务器同步。
哨兵模式
反客为主的自动版,能够后台监控主机,如果主机挂掉了根据投票数自动将从服务器转换为主服务器。
sentinel.conf
1 | # 其中mymaster为监控对象起的服务器名称, 1 表示至少有多少个哨兵同意重新选取主机。 |
运行哨兵
1 | redis-sentinel sentinel.conf |
选取主机原则:
- 优先级最高的 ,replica-priority 值越小优先级越高
- 偏移量最大 ,即优先选择同步数据最全的从机
- runid最小的
集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
无中心化配置,任何一台主机或从机都能成为集群的入口,它们之间都能相互通信。
集群配置:
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换
reids6179.conf
1 | include /home/bigdata/redis.conf # 公共配置 |
合并:
1 | cd /opt/redis-6.2.1/src |
使用实际ip !
通过插槽slot来实现数据分布存储
主节点下线,从节点自动升为主节点
某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
应用问题解决
缓存穿透
查询存储层中根本不存在的数据,导致每次请求都要到存储层去查询。
解决方案:
缓存空对象,并设置过期时间
采用布隆过滤器
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
缓存击穿
短时间内查询大量key集中过期,大量请求直接指向数据库,最终请求到数据库,造成数据库崩溃。
解决方案:
- 将缓存过期时间设置为随机数
缓存雪崩
缓存层宕机或者支撑不了当前的并发,导致整个系统崩溃。
解决方案:
保证缓存层的高可用,使用哨兵、主从架构
限流熔断
分布式锁
随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的Java API并不能提供分布式锁的能力。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁主流的实现方案:
基于数据库实现分布式锁
基于缓存(Redis等)
基于Zookeeper
每一种分布式锁解决方案都有各自的优缺点:
- 性能:redis最高
- 可靠性:zookeeper最高
1 | ("/testLock") |
删除策略
惰性删除
数据到达超时时间的,不立即处理,等下次访问该数据的时候,再去删除。
定时删除
当 key设置过期时间的时候,创建一个定时器事件,当 key 过期时间到达时,由定时器任务立即执行对 key 的删除操作,删除操作先删除存储空间,再移除掉过期的key。
定期删除
周期性轮询 Redis 库中的时效性数据,采取随机抽取的策略,利用过期数据占比的方式控制删除频度。
淘汰策略
加入键的时候如果过限时采用淘汰策略删除键:
- LRU 最近最少使用
- LFU 使用频率最少