MQ简介
MQ(Message Queue),别名为消息中间件。通过典型的生产者和消费者模型,生产者向消息队列中不断生产消息,消费者从消息队列中不断获取消息。因为消息的产生和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,实现了系统之间的解耦。通过利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
应用场景:
- 异步处理
- 应用解耦
- 流量削峰
- 日志处理
- 消息通讯
主流的消息中间件
ActiveMQ:java语言实现,万级数据吞吐量,处理速度ms级,主从架构,成熟度高
ActiveMQ,是Apache出品,最流行的,能力强劲的开源消息组件。它是一个完全支持JMS规范的的消息中间件。丰富的API,多种集群架构模式让ActiveMQ在业界成为老牌的消息中间件,在中小型企业颇受欢迎。
Kafka:scala语言实现,十万级数据吞吐量,梳理速度ms级,分布式架构,功能较少,应用于大数据较多
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
RocketMQ:java语言实现,十万级数据吞吐量,处理速度ms级,分布式架构,功能强大,拓展性强
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。
RabbitMQ:erlang语言实现,万级数据吞吐量,处理速度us级,主从架构
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
- AMQP(advanced message queuing protocol)在2003年时被提出,最早用于解决金融领域不同平台之间的消息传递交互问题。顾名思义,AMQP是一种协议,更准确的说是一种binary wire-level protocol(链接协议)。这是其和JMS的本质差别,AMQP不从API层进行限定,而是直接定义网络交换的数据格式。这使得实现了AMQP的provider天然性就是跨平台的。
RabbitMQ的使用
使用Docker快速安装并启动
1 | # 服务端端口5672 客户端端口 15672 |
访问rabbitmq的管理界面
地址为 ip:15672
添加用户,以及虚拟主机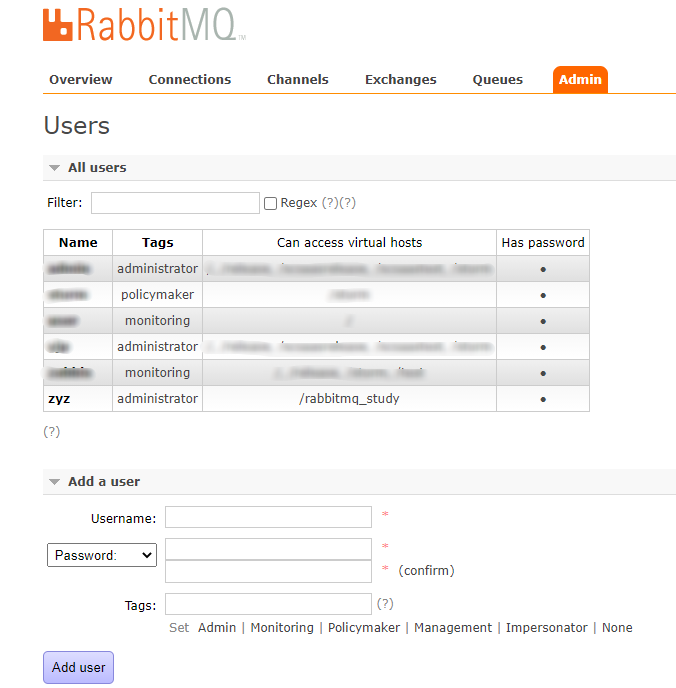
还需要在当前登录管理界面的用户下添加新增的虚拟主机地址,否则监控不到在新增虚拟主机下的创建的消息队列!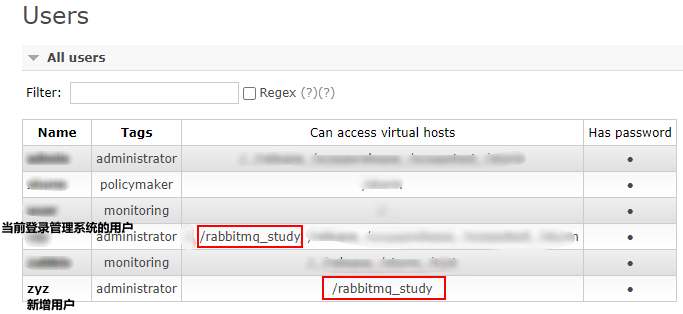
使用java创建消息队列模型
引入依赖
1 | <dependency> |
第一种模型(直连)
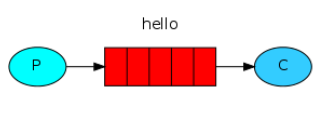
- P:生产者,也就是要发送消息的程序。
- C:消费者:消息的接收者,会一直等待消息到来。
- queue:消息队列,图中红色部分。类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
生产者的实现:
1 | // 生产消息 |
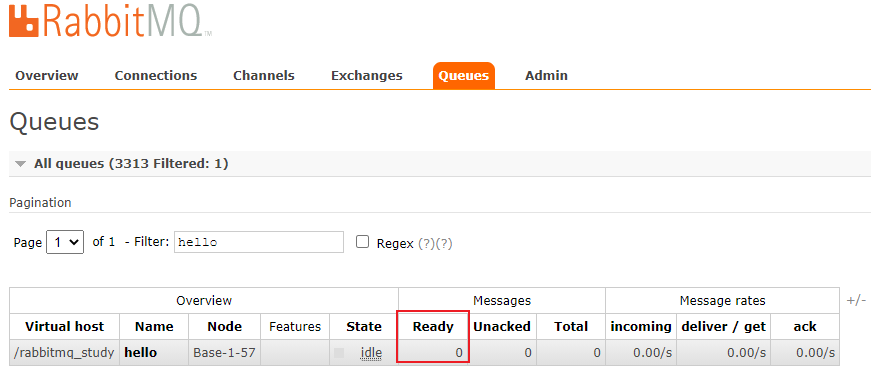
在管理界面查看创建的mq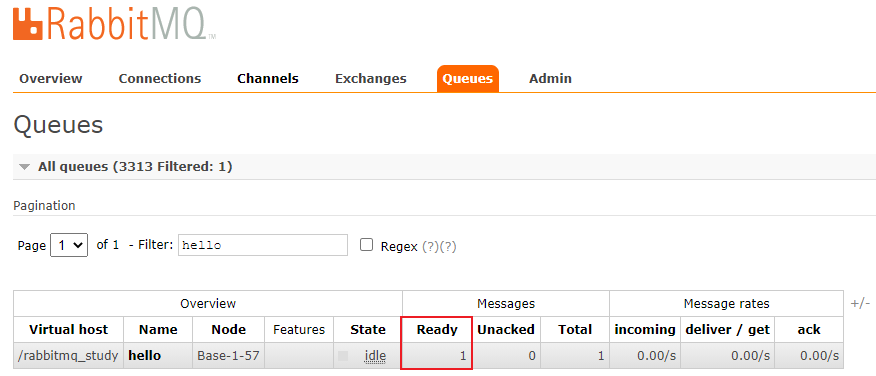
消费者的实现:
1 | // 接收消息 |
封装工具类
1 | public class RabbitMQUtils { |
第二种模型(work queue)
Work queues,也被称为(Task queues),任务模型。当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。此时就可以使用work 模型:让多个消费者绑定到一个队列,共同消费队列中的消息。队列中的消息一旦消费,就会消失,因此任务是不会被重复执行的。
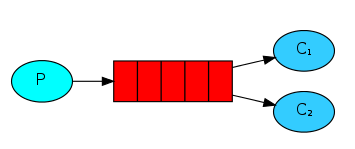
- P:生产者:任务的发布者
- C1:消费者-1,领取任务并且完成任务,假设完成速度较慢
- C2:消费者-2:领取任务并完成任务,假设完成速度快
生产者
1 | public class Provider { |
消费者-1
1 | public class Consumer1 { |
消费者-2
1 | public class Consumer2 { |
- 默认为平均分发,将消息平均分配给每个消费者,这种分发方式叫做循环。
通过关闭自动确认和开启手动确认来保证 “能者多劳 ”——消费快的消费者消费更多的消息。
1 | public class Consumer1 { |
第三种模型(广播)
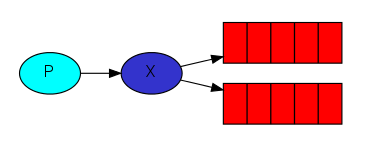
在广播模式下,消息发送流程是这样的:
- 可以有多个消费者
- 每个消费者有自己的queue(队列)
- 每个队列都要绑定到Exchange(交换机)
- 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。
- 交换机把消息发送给绑定过的所有队列
- 队列的消费者都能拿到消息。实现一条消息被多个消费者消费
生产者:
1 | public class Provider { |
消费者:
1 | public class Customer { |
此时生产者生产的一条消息可以被多个消费者同时消费。
第四种模型(路由)
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
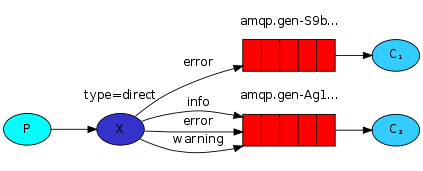
- P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
- X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
- C1:消费者,其所在队列指定了需要routing key 为 error 的消息
- C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
生产者:
1 | public class MsProvider { |
消费者:
1 | public class MsConsumer { |
Routing模型之topic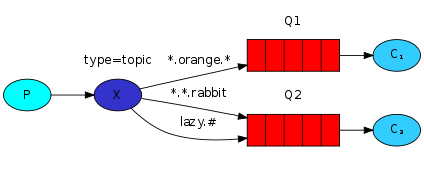
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!这种模型Routingkey 一般都是由一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
audit.# 匹配audit.irs.corporate或者 audit.irs 等audit.* 只能匹配 audit.irs