进程与线程
进程
进程是程序的一次执行过程,是指程序及其数据在处理机上顺序执行时所发生的活动,一组具有独立功能的程序在数据集合上的一次活动,它是系统进行资源分配和调度的独立单位。
线程
为了提高系统的执行效率,减少处理机的空转时间和调度切换的时间,以及便于系统管理。提出了线程的概念,将一个进程分为多个线程,线程作为调度和分派的基本单位。线程执行开销小,但不利于资源的管理和保护。
线程的三个基本状态:执行,就绪,阻塞
线程的两个基本类型
- 用户级进程:在用户级线程中,有关线程管理的所有工作都由应用程序完成,内核意识不到线程的存在。
- 系统级进程:在内核级线程中,线程管理的所有工作都由内核完成,应用程序没有进行线程管理的代码,只有一个到内核级线程的编程接口。
并发与并行
并行:
- 并行是指同一时刻内发生两个或多个事件
- 并行是在不同实体(处理机)上的多个事件
并发:
- 并发性是指同一时间间隔内发生两个或多个事件
- 并发是在同一实体上的多个事件
并行是针对进程的,并发是针对线程的。
并发的三大特性:
- 原子性:一个操作在cpu上执行时不可能中途暂停然后再调度。
- 可见性:多个线程对变量的修改是可见的。
- 有序性:虚拟机在进行代码编译时,对于那些改变顺序之后不会对最终结果造成影响的代码,虚拟机不一定会按照我们写的代码的顺序来执行,有可能将他们重排序。实际上,对于有些代码进行重排序之后,虽然对变量的值没有造成影响,但有可能会出现线程安全问题。
synchronized保证原子性;volatile保证可见性,有序性;final保证可见性
Java实现多线程
创建多线程的四种方式:
- 继承Thread类,重写run()方法
- 实现Runnable接口,重写run()方法
- 实现Callable接口,重写call()方法
- 使用线程池
实现Runnable接口
1 | class MyThread2 implements Runnable{ |
实现Callable接口:
1 | class MyThread3 implements Callable{ |
Callable与Runnable 两点不同:
第一,可以通过 call()获得返回值。前两种方式都有一个共同的缺陷,即在任务执行完成后 ,无法直接获取执行结果需要借助共享变量等获取 ,而 Callable和Future则很好地解决了这个问题;
第二, call()可以抛出异常。而 Runnable 要通过 setDefaultUncaughtExceptionHandler() 的方式才能在主线程中捕捉到子线程异常。
使用线程池
1、降低创建和销毁线程的资源消耗,提高线程的利用率;
2、提高响应速度;
3、提高线程的可管理性。
线程池的使用:
1 | public class ThreadPoolUtils { |
corePoolSize核心线程数,也就是正常工作时创建的线程数,创建后不会销毁,是一种常驻线程。maxinumPoolSize最大线程数,表示允许创建的最大线程数,当核心线程数不够使用时创建,线程的总数不会超过最大线程数。keepAliveTime表示超出核心线程数之外的线程的空闲存活时间 。unit时间单位。workQueue任务队列,核心线程使用完后,将任务放入任务队列,当任务队列满后再创建新的线程。threadFactory线程工厂,用于创建线程。handler任务拒绝策略。当关闭线程池后,任务队列里面没有执行完的任务再向线程池提交时会拒绝;当线程达到最大线程数时继续提交任务也会拒绝。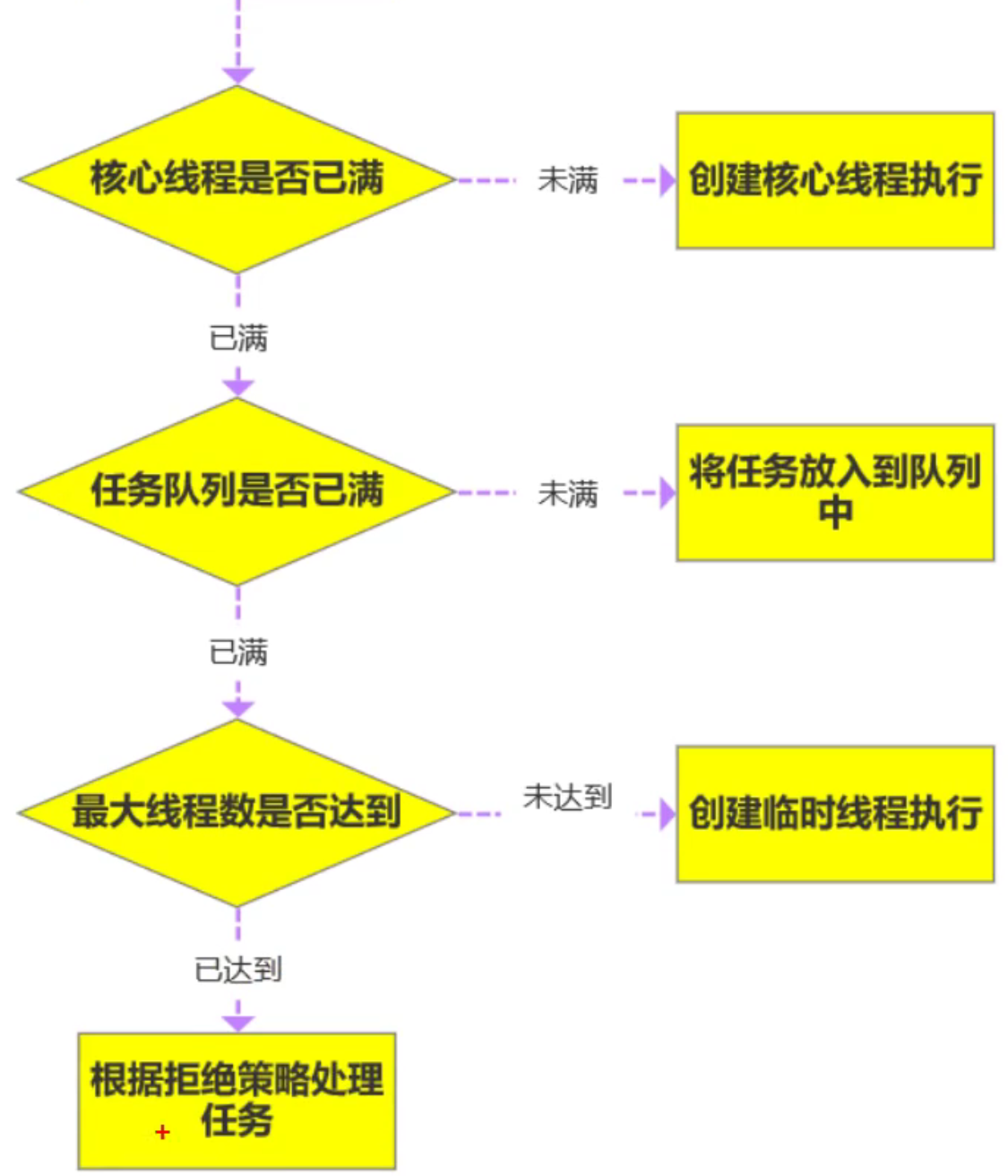
1 | public class ThreadTest4 { |
Java实现多线程要注意的细节
run()与start()的区别:
run():只是封装了被线程执行的代码,直接调用就是普通方法start():首先启动了线程,然后再由jvm去调用该线程的run()方法
java虚拟机的启动是单线程还是多线程的?
- 是多线程的,不仅启动main线程,还至少启动了垃圾回收线程
一般使用多线程的哪种实现方式?
使用实现Runnable接口的方式,避免了单继承的局限性
应该将并发运行任务和运行机制解耦
Thread中的常用方法
获取线程名:getName()
获取当前线程名:Thread.currentThread.getName()
设置线程名:setName()
设置守护进程:setDeamon(boolean on)
- 守护进程
- 就是为其他进程服务的进程,例如垃圾回收的进程
- 当别的用户进程执行完后,虚拟机就会退出,守护进程就会停止
- 设置守护进程时,必须要在线程启动前设置
setDeamon(true),启动后设置会抛出异常, - 使用守护进程不要访问共享资源,因为他们可能在任何时候就挂掉了
- 守护进程中产生的新进程也是守护进程
设置线程优先级:setPriority()
线程优先级高仅仅表示线程获取的CPU时间片的几率高,但这不是一个确定的因素!
线程生命周期方法:
sleep()方法
调用sleep方法会进入计时等待状态,等时间到了,进入的是就绪状态而并非是运行状态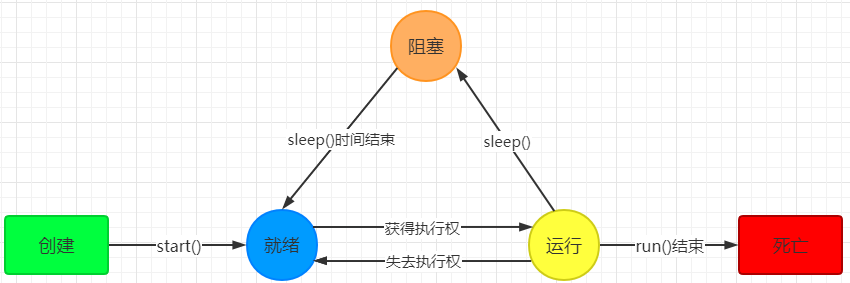
yield()方法
暂停当前正在执行的线程,让线程进入就绪状态,把执行机会让给优先级相同或更高的线程,不确保真正的让出。
join()方法
使调用的线程先执行,执行完后再执行其他线程;低优先级的线程也可以获得执行。
wait()方法
wait()是Object类中定义的native方法;
一旦线程执行此方法,当前线程就会进入阻塞状态,并释放锁
notify()方法
notify()也是Object类中定义的native方法;
一旦执行此方法就会唤醒被wait的一个线程。若有多个线程被wait,则唤醒优先级高的
notifyAll()方法
也是Object类中的方法,唤醒所有wait的线程
interrupt()方法
线程中断在之前的版本中有stop()方法,因为存在安全问题被设置过时了。
stop()方法可以让一个线程A终止一个线程B,被终止的线程会立即释放锁,这可能会让对象处于不一致的状态。
一般使用interrupt()来请求终止线程。
- interrupt不会真正停止一个线程,仅仅是发出一个中断信号,告诉他应该要结束了
- 让线程自己处理,到底是中断还是继续执行
1 | Thread t1 = new Thread( new Runnable(){ |
如果阻塞线程调用了interrupt()方法,那么会抛出异常,设置标志位为false,同时该线程会退出阻塞。
Thread.interrupted() :第一次使用返回true,并清除中断标志位,第二次返回false
synchronized锁与Lock锁
synchronized锁使用:
方式一:同步代码块
将可能出现线程安全问题的代码使用synchronized关键字包裹
1 | synchronized(/*锁*/){// 要保证是同一把锁 |
方式二:同步方法
将可能出现线程安全问题的代码块封装成一个同步方法
1 | public void synchronized func(){ |
Lock锁
通过显式定义同步锁对象,即Lock对象,来实现同步。
1 | class buyTicket implements Runnable{ |
synchronized和ReentrantLock都是悲观锁的实现,共享资源每次只给一个线程使用,其他线程阻塞,用完后再把资源释放给其他线程。
悲观锁
总是假设最坏的情况,每次操作数据都会加锁,其他线程阻塞直到获得锁。例如数据库中的行锁,表锁,读锁,写锁,Java中的synchronized和ReentrantLock独占锁等。适用于写操作比较多的场景,保证数据的一致性。
乐观锁
总是假设最好的情况,每次操作数据时都不会加锁,只是在更新数据前判断在此期间该数据有没有被修改过,通常使用版本号机制和CAS算法实现。适用于读操作比较多的场景,可提高吞吐量。
版本号机制
在数据表中添加version版本号字段,用来表示数据被修改的次数,数据被修改时加1,线程在提交更新操作时会将读取的version与数据库中的version对比,相等才更新,否则重试直到更新成功。
CAS算法
Compare And Swap 比较交换,也叫非阻塞同步,在进行更新操作时会将读取到的值V与当前要修改的值A进行比较,如果相等就认为在此期间该值没有被其他线程修改过,则会提交更新操作将A修改为更新值B,否则一直自旋,直到成功。
缺点:
- ABA问题,当前值由A改到其他值,然后又改回A,CAS算法就会判断该值没有被修改过。
AtomicStampedReference类通过控制变量的版本来保证 CAS 的正确性。 - 自旋CAS,长时间不成功会带来cpu开销加大。
在Jdk 1.6之后,对Synchronized进行了优化,主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁 和 轻量级锁 以及其它各种优化。synchronized的底层实现主要依靠 Lock-Free 的队列,基本思路是自旋后阻塞,提高了吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
避免死锁
1、注意加锁顺序,保证每一个线程按同样的顺序进行加锁;
2、设置超时时间;
3、死锁检查,预防死锁的发生。