Lambda表达式
Lambda是一个匿名函数,可以理解为一段可传递的代码,将代码将数据一样进行传递。
1 | /** |
Lambda表达式的应用
forEach 遍历Map
1 | Map<String,Object> map = new HashMap<String,Object>(); |
forEach 遍历List
1 | List<Integer> list = new ArrayList<Integer>(); |
创建并开启线程
1 | new Thread(()->System.out.println("new Thread start")).start(); |
Stream 流
以集合为例,一个流式处理的操作我们首先需要调用stream()函数将其转换成流,然后再调用相应的中间操作达到我们需要对集合进行的操作,比如筛选、转换等,最后通过终端操作对前面的结果进行封装,返回我们需要的形式。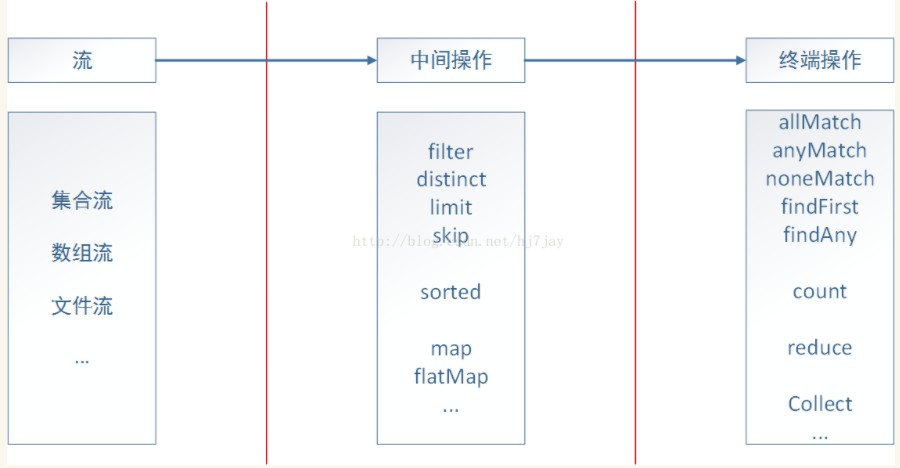
常用api的使用
创建实体类
1 |
|
初始化
1 | List<User> list = new ArrayList<User>(){ |
filter 过滤
1 | // 筛选出学校是清华大学的所有用户并打印输出他们的姓名 |
输出结果:
1 | 张三 李四 王五 赵六 |
distinct
1 | // distinct 获取所有user的年龄(年龄不重复) |
输出结果:
1 | 18 20 16 19 25 22 21 |
limit 返回前n个元素的流,当集合长度小于n时,则返回所有集合
1 | // 获取年龄是偶数的前2名user |
1 | 张三 李四 |
sorted
1 | // 将所有user按年龄从大到小排序 |
输出结果:
1 | [User{id=5, name='田七', age=25, school='北京大学'}, User{id=8, name='小华', age=22, school='浙江大学'}, User{id=9, name='小丽', age=21, school='浙江大学'}, User{id=2, name='李四', age=20, school='清华大学'}, User{id=7, name='小红', age=20, school='北京大学'}, User{id=4, name='赵六', age=19, school='清华大学'}, User{id=1, name='张三', age=18, school='清华大学'}, User{id=10, name='小何', age=18, school='浙江大学'}, User{id=3, name='王五', age=16, school='清华大学'}, User{id=6, name='小明', age=16, school='北京大学'}] |
skip 跳过几个元素再输出
1 | // 跳过前两个user,输出之后的user |
输出结果:
1 | [User{id=3, name='王五', age=16, school='清华大学'}, User{id=4, name='赵六', age=19, school='清华大学'}, User{id=5, name='田七', age=25, school='北京大学'}, User{id=6, name='小明', age=16, school='北京大学'}, User{id=7, name='小红', age=20, school='北京大学'}, User{id=8, name='小华', age=22, school='浙江大学'}, User{id=9, name='小丽', age=21, school='浙江大学'}, User{id=10, name='小何', age=18, school='浙江大学'}] |
map 映射元素结果
1 | // 筛选出学校是清华大学的所有学生 |
输出结果:
1 | [张三, 李四, 王五, 赵六] |
匹配
1 | // allMatch |
输出结果:
1 | false |
findFirst 用于返回满足条件的第一个元素
1 | Optional<User> first = list.stream() |
输出结果:
1 | User{id=1, name='张三', age=18, school='清华大学'} |
counting 计算个数
1 | // Long counting = list.stream().collect(Collectors.counting()); |
输出结果:
1 | 总人数:10 |
maxBy minBy 计算最大值 最小值
1 | Integer maxAge = list.stream() |
输出结果:
1 | 最大年龄:25 |
summingInt、summingLong、summingDouble 计算总和
1 | Integer ageSum = list.stream().collect(Collectors.summingInt(User::getAge)); |
输出结果:
1 | 年龄总合为:195 |
averageInt、averageLong、averageDouble 计算平均值
1 | Double ageAverage = list.stream().collect(Collectors.averagingInt(User::getAge)); |
输出结果:
1 | 年龄平均值:19.5 |
summarizingInt、summarizingLong、summarizingDouble
一次性查询元素个数、总和、最大值、最小值和平均值
1 | IntSummaryStatistics collect = list.stream() |
输出结果:
1 | IntSummaryStatistics{count=10, sum=195, min=16, average=19.500000, max=25} |
joining 字符串拼接
1 | String names = list.stream() |
输出结果:
1 | 张三,李四,王五,赵六,田七,小明,小红,小华,小丽,小何 |
groupingBy 分组
1 | // 根据大学划分用户 |
输出结果:
1 | {浙江大学=[User{id=8, name='小华', age=22, school='浙江大学'}, User{id=9, name='小丽', age=21, school='浙江大学'}, User{id=10, name='小何', age=18, school='浙江大学'}], 北京大学=[User{id=5, name='田七', age=25, school='北京大学'}, User{id=6, name='小明', age=16, school='北京大学'}, User{id=7, name='小红', age=20, school='北京大学'}], 清华大学=[User{id=1, name='张三', age=18, school='清华大学'}, User{id=2, name='李四', age=20, school= |
partitioningBy 分区
1 | // 按照是否是清华大学的user将所有user分为两个部分 |
输出结果:
1 | {false=[User{id=5, name='田七', age=25, school='北京大学'}, User{id=6, name='小明', age=16, school='北京大学'}, User{id=7, name='小红', age=20, school='北京大学'}, User{id=8, name='小华', age=22, school='浙江大学'}, User{id=9, name='小丽', age=21, school='浙江大学'}, User{id=10, name='小何', age=18, school='浙江大学'}], true=[User{id=1, name='张三', age=18, school='清华大学'}, User{id=2, name='李四', age=20, school='清华大学'}, User{id=3, name='王五', age=16, school='清华大学'}, User{id=4, name='赵六', age=19, school='清华大学'}]} |